CUDA SIMT
CUDA 笔记 SIMT
最近在瞎看,整理了下看的结果,主要还是来源于NVIDIA的官方文档
GPU采用了SIMT(Single-Instruction, Multiple-Thread)的架构来管理大量的并行的线程。
- 单线程内的指令级并行(利用pipeline)
- 不同线程间的thread-level并行
由于GPU面相吞吐,在单核心的执行中,没有CPU端的乱序执行和分支预测机制,且采用小端表示法
SIMT
32个线程称为一个warp,在SM上加载的若干个block以warp的单位进行调度执行,调度器称为warp scheduler。每个warp中线程的id都是连续的。
但是同一个warp作为一个并行执行单元,其内部的所有线程的执行需要同步,也就是说存在分支发散的问题。分支执行中GPU会执行这个warp中所有线程的分支并且在执行其他线程的分支时让不执行这个分支的线程等待。也是就常说的 Branch divergence ,分支发散这里不详细讲,在GPU优化中这是个重要的部分,好的分支策略往往可以明显的提升加速比。
SIMT事实上是NVIDIA提出来的概念,可以理解成升级版SIMD,SIMD的编程需要软件层面明确SIMD的宽度,而SIMT相当于隐藏了这点,编程层面其实可以忽略掉warp的大小来对每个线程进行指定(当然事实上还是得追求速度,需要考虑warp的因素)
事实上在Volta架构前,32个线程确实是完全同步的,因为虽然每个线程的寄存器状态不同,但是都共享同一个指令计数器。Volta架构引入了一个*Independent Thread Scheduling*的东西,这样每个线程都有自己的指令计数器和调用栈,并且可以在每个线程的粒度上产生执行,以便更好地利用执行资源或允许一个线程等待另一个线程生成数据。使得程序可以在sub-warp级别的并行。
但是事实上依然没改变SIMT的属性,这32个线程还是执行同样的指令,不在这个条件分支内active的线程依然会等待,该出现的分支发散一样会发散,指令发射的效率也没啥提升。只是在隐藏延迟方面获得了提升,如下图

这样做对性能的关键影响在于:不同的分支之间,可以通过交错执行来达到相互帮助隐藏延迟的目的,这在之前的架构中只能通过调度其他的warp来实现
这样还会引来另一个问题,就是原本在Volta架构之前假定warp内同步的程序可能会带来不确定的结果。尤其是一些warp_shfl的程序,所以新的cuda里还提供了更安全的__shfl_xxx_sync()函数,具体的问题可以参考NVIDIA官方Programming Guide。
其他
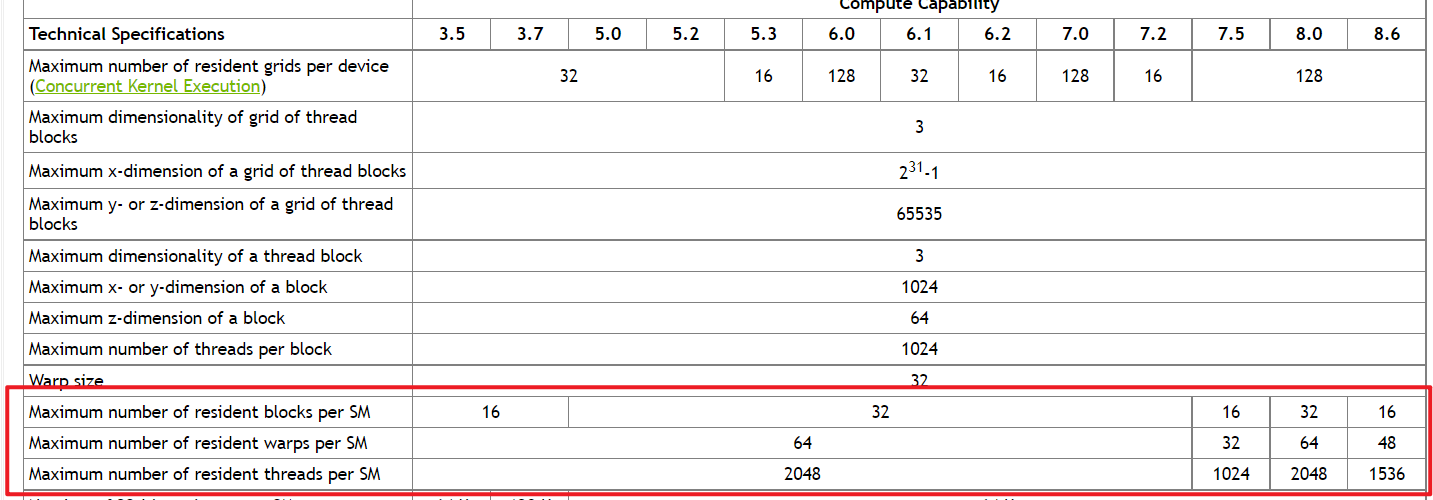
值得一提的是,每个流多处理器能驻存的warp数和block数是有限制的,这个不仅仅是我们常说的是寄存器和SMem的使用的限制,也有硬件的限制。可以在官方文档中查到,如下图所示